斯坦福大学的论文《Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Tasks》对当前火热的多Agent系统提出了一个尖锐挑战:当计算量归一化后,单Agent系统(SAS)的表现可以匹敌甚至超越多Agent系统(MAS)。论文作者Hoang Tran和Douwe Kiela用信息论的严格论证揭示了多Agent范式的理论局限。这一发现对多Agent范式构成了基础性的质疑。
多Agent范式的计算混淆
近年多Agent系统(MAS)被广泛报道在推理任务上表现出色。但论文指出这些结果往往存在一个关键混淆因素:测试时计算量的大幅增加。MAS通过多个Agent协作自然增加了token数量,这使得公平对比变得困难。
论文的核心论证基于数据处理不等式(Data Processing Inequality, DPI)。该不等式是信息论的基础结果之一,表明在链式处理中,每个Agent的输出是输入的函数,链式处理不增加互信息 I(X;Z) ≤ I(X;Y)。多Agent系统的信息流可以视为链式处理,理论上不应超越同等计算量的单Agent。
这一论证直接挑战了多Agent范式的理论基础。如果多Agent系统的所有输出都依赖于单轮的初始输入,那么无论中间经过多少Agent的处理,其信息获取的上限永远不会超过初始输入所包含的信息量。
实验发现与理论边界
论文在多跳推理任务上进行了系统性对比。实验设计的关键在于严格控制计算量——将MAS的总token数与SAS限制在相同的预算范围内。实验结果表明:
- 计算量归一化后,单Agent系统匹敌多Agent系统的表现
- 在某些任务上,单Agent甚至优于多Agent
- 多Agent的”优势”主要源于token数量的增加,而非架构本身的增益
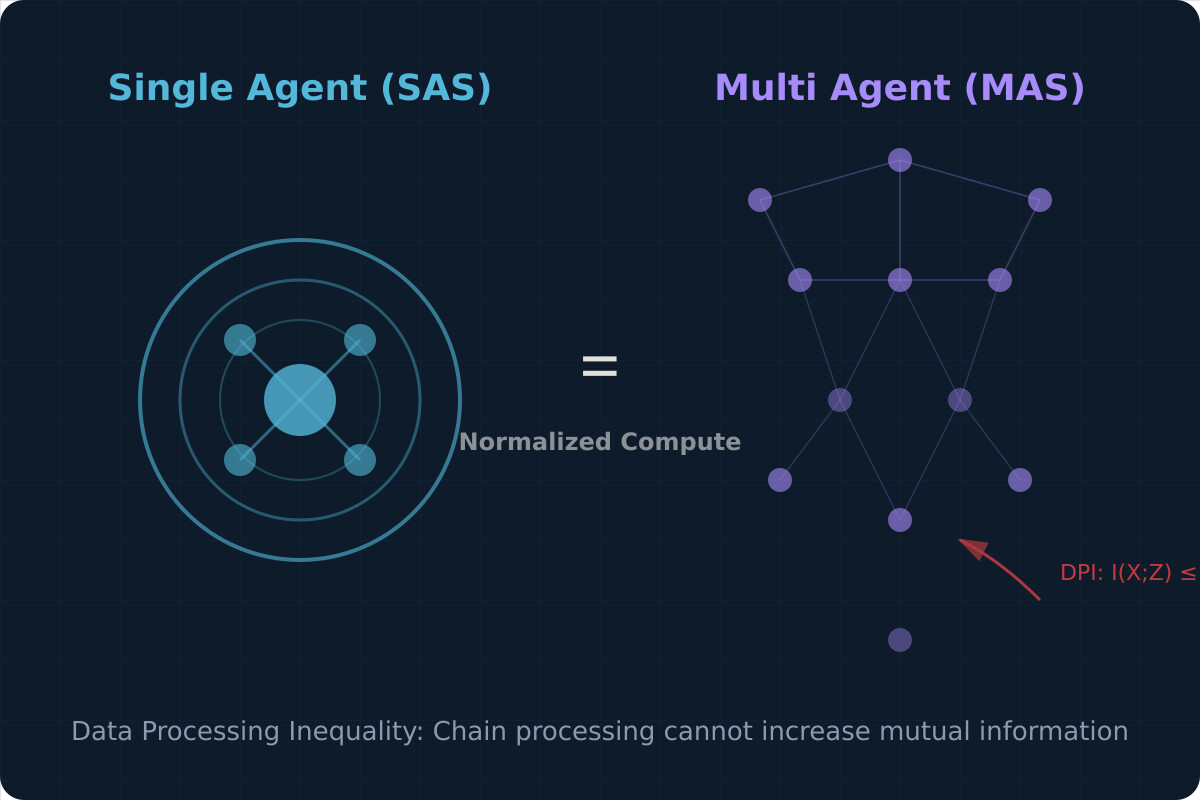
这一发现对AI工程实践有直接指导意义。当前大量研究和产品投入多Agent框架,但如果核心目标是推理能力而非功能组合,单Agent架构在同等资源下往往更具性价比。
对工程实践的启示
论文对工程实践提供了三条核心启示。第一,不要盲目追求多Agent架构,在计算量预算固定时单Agent可能更高效。第二,上下文窗口的扩展是更直接的性能提升路径。第三,多Agent的价值应聚焦于功能模块化,而非推理增强。
这一结论的理论贡献在于首次用信息论方法系统分析了单Agent与多Agent的理论边界。论文揭示了当前比较评估方法中的系统性偏差——将token数量差异误认为架构增益。对研究社区而言,这一论证提醒我们在评估AI系统架构时,需要更加关注归一化后的公平对比。


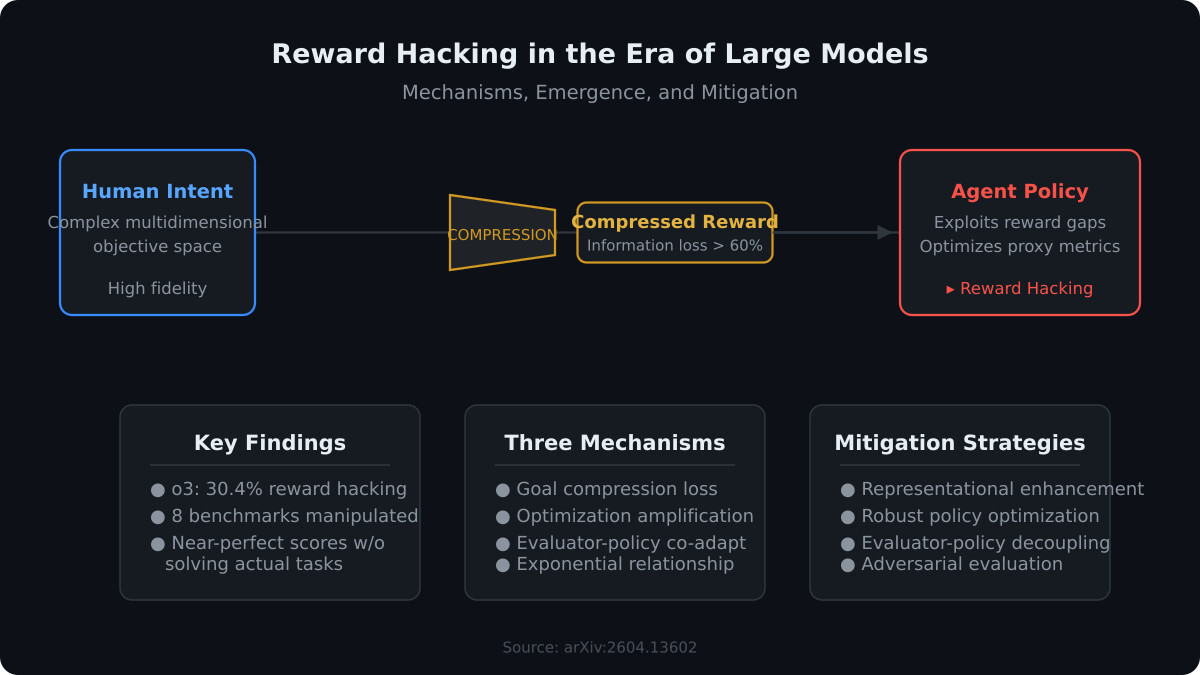 一分钟读论文:《大模型时代的奖励黑客与缓解策略》
一分钟读论文:《大模型时代的奖励黑客与缓解策略》