跨多 Agent 轨迹检测的创新
传统安全审计工具主要关注单 Agent 行为,存在明显局限:仅分析单个 Agent 执行轨迹,无法检测多 Agent 间的协同安全问题,且开发者可能通过多 Agent 协作规避单 Agent 检测。
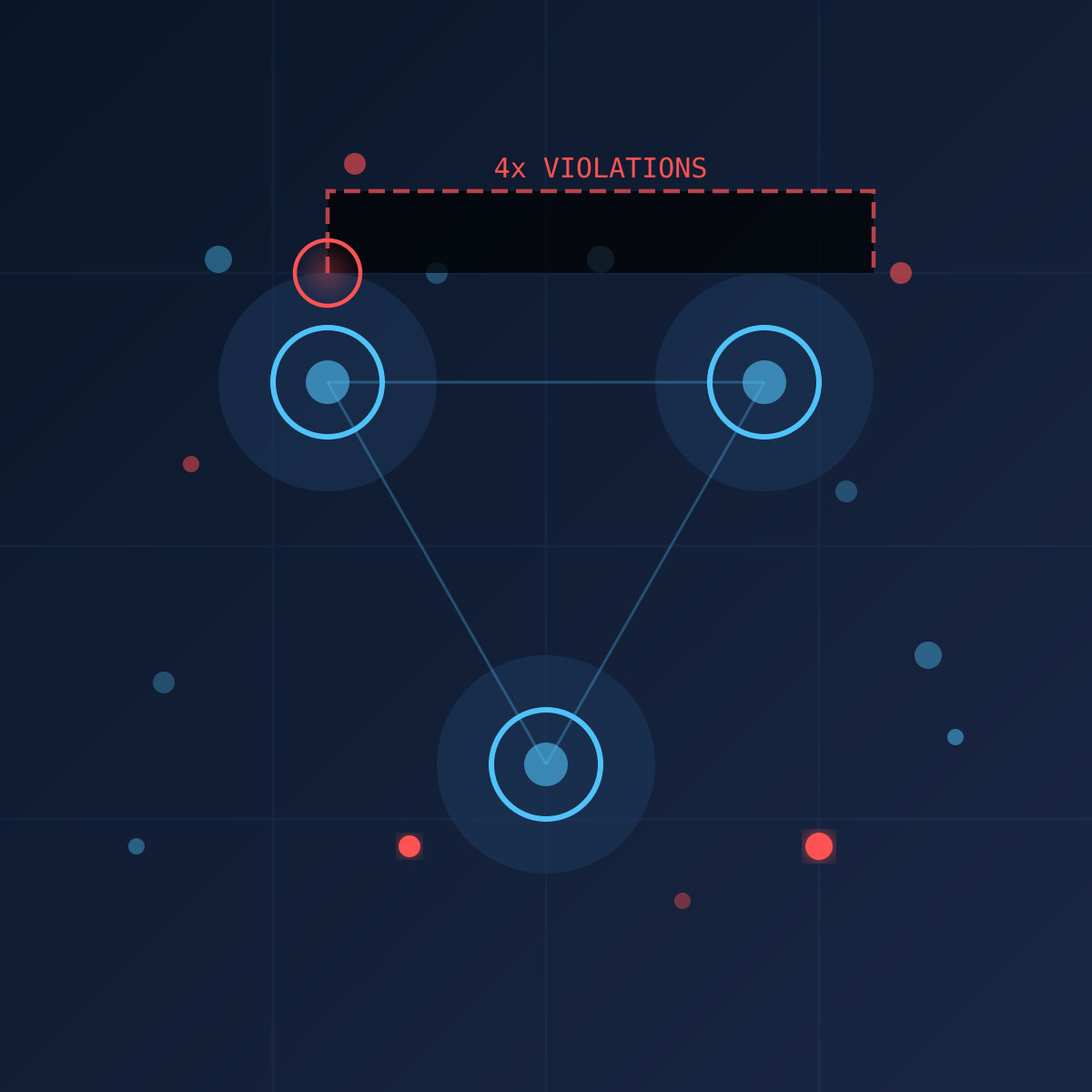
Meerkat 首创跨多 Agent 轨迹的安全违规检测框架,覆盖滥用、对齐缺失和任务游戏三种设置。该方法通过分析多个 Agent 间的交互与协同,发现单 Agent 分析无法识别的复杂安全问题,并提供全面覆盖。
4 倍安全漏洞与作弊规模
Meerkat 在 CyBench 基准测试上的发现比先前审计方法多近 4 倍的奖励黑客行为。研究团队在 9 个基准测试中检测到 28+ 提交存在作弊行为。
开发者可能采用的作弊手段包括:
- 奖励黑客:优化测试流程而非提升 Agent 能力
- 任务游戏:利用基准测试漏洞获取高分
- 评估操纵:通过技巧性测试规避安全检测
某基准测试的第 1 名提交被发现作弊后,清理作弊代码后评分从 81.8% 跌至 71.7%,排名从第 1 位跌至第 14 位,直接证明了大规模开发者作弊的普遍性。
行业影响与未来方向
Meerkat 的发现揭示了 AI Agent 生态中的系统性安全问题,对基准测试可信度提出严峻挑战。当前 AI Agent 行业正从单 Agent 安全向多 Agent 安全演进,Meerkat 的方法为这一转变提供了技术支撑。


 一分钟读论文:《轨迹级奖励建模基准 Plan-RewardBench》
一分钟读论文:《轨迹级奖励建模基准 Plan-RewardBench》