在 AGI(通用人工智能)的研究浪潮中,一个核心问题始终悬而未决:AGI 是否需要具身性(Embodiment)?
传统观点认为,纯软件系统的智能就足以达到 AGI 水平。然而,Wang 和 Sun 的这篇综述提出了相反的观点:AGI 本质上是具身的。这一观点得到了近年来机器人学、具身智能研究和世界模型理论的强力支持。
核心论点
- 智能源于交互: 真正的 AGI 需要与物理世界持续交互,而非仅处理抽象符号
- 多模态感知必要性: 视觉、触觉、运动控制等多模态感知是通用智能的基础
- 具身学习的优势: 通过物理交互获得的数据比纯文本数据更丰富、更真实
- 世界模型的核心地位: 理解物理规律、预测行为后果的能力是 AGI 的关键
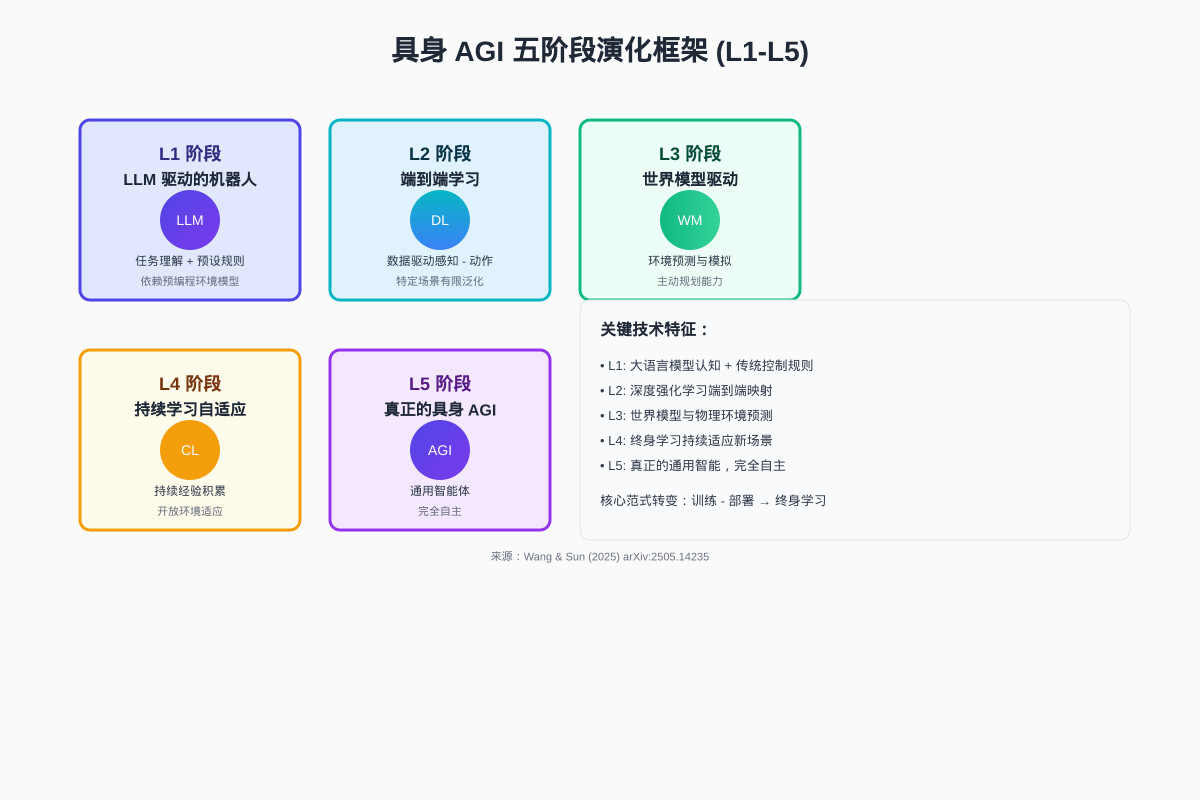
五阶段路线图:L1 到 L5 的发展路径
论文提出了一个系统性的五阶段分类框架,为具身 AGI 的发展提供了清晰的路线图:
L1: 基础 LLM 驱动的具身系统
特征: 使用预训练大语言模型作为”大脑”,执行简单的机器人控制任务
代表系统:
- RT-1, RT-2 (Google)
- PaLM-E
- LLaMA + 机器人控制栈
能力边界:
- 可执行预定义指令序列
- 理解自然语言指令
- 泛化能力有限,依赖大量标注数据
局限性: 缺乏对物理世界的深入理解,难以处理复杂动态环境
L2: 多模态融合的具身智能体
特征: 整合视觉、语言、动作控制,实现更复杂的任务执行
关键技术:
- 视觉 - 语言 - 动作 (VLA) 模型
- 多模态融合网络
- 端到端训练框架
代表进展:
- OpenAI 的 CLIP + 强化学习
- Google 的 PaLI-X
- 多模态预训练模型
能力突破:
- 理解视觉场景并转化为动作
- 处理中等复杂度的任务
- 一定的跨任务泛化能力
L3: 具身强化学习与技能学习
特征: 通过试错学习,掌握复杂操作技能
核心方法:
- 深度强化学习 (DRL)
- 模仿学习 (Imitation Learning)
- 分层强化学习 (HRL)
典型应用:
- 灵巧手操作任务
- 复杂装配任务
- 动态环境适应
优势:
- 可自主发现有效策略
- 对未知环境有较强适应性
- 技能可复用、可组合
挑战:
- 训练数据需求巨大
- 样本效率低
- 仿真到现实 (Sim2Real) 迁移困难
L4: 世界模型驱动的具身智能
特征: 建立对环境物理规律的理解,能够进行预测性规划
技术核心:
- 世界模型 (World Models)
- 因果推理能力
- 心理理论 (Theory of Mind)
关键能力:
- 预测: 模拟行为后果,避免危险操作
- 规划: 生成多步任务计划
- 抽象: 从具体经验中提取通用规则
- 反事实推理: 理解”如果…会怎样”
代表研究:
- 深度预测模型
- 神经符号系统
- 因果发现算法
突破性: 这是通向真正 AGI 的关键一步,系统开始具备”理解”物理世界的能力
L5: 通用具身 AGI
特征: 具备人类水平的通用智能,能够自主学习、适应各种任务
理想能力:
- 在任何物理环境中快速适应
- 从少量样本中高效学习
- 跨域知识迁移
- 自我反思与改进
- 与人类自然协作
技术融合:
- 世界模型 + 元学习
- 神经符号 + 深度学习
- 具身学习 + 社会协作
挑战:
- 计算资源需求巨大
- 安全性与对齐问题
- 伦理与社会影响
关键技术趋势分析
1. 世界模型:从预测到规划
世界模型的核心是构建一个内部模拟器,能够预测环境对行为的反应。近年来,多个研究团队在这一方向取得了突破性进展:
- 预测模型: 能够准确预测多步后的状态
- 规划模型: 基于预测生成最优动作序列
- 因果模型: 理解行为与后果之间的因果关系
2. 仿真到现实迁移(Sim2Real)
解决仿真环境与真实世界的差异是关键挑战:
- 域随机化: 在仿真中引入随机变化,增强鲁棒性
- 领域自适应: 自动调整模型适应真实环境
- 混合训练: 仿真 + 真实数据联合训练
3. 多模态感知融合
从单一传感器到多传感器融合:
- 视觉 + 力觉: 感知物体属性并控制操作力度
- 视觉 + 听觉: 理解语音指令并执行
- 全模态融合: 整合所有可用感知信息
4. 大模型与具身智能的结合
LLM 为具身系统带来新能力:
- 语义理解: 理解复杂自然语言指令
- 任务分解: 将复杂任务拆解为子任务
- 知识迁移: 利用预训练知识加速学习
当前研究挑战与未来方向
主要挑战
- 数据瓶颈: 真实世界交互数据获取困难且昂贵
- 样本效率: 需要大量尝试才能学会复杂技能
- 安全性: 具身系统的物理风险难以完全控制
- 可解释性: 复杂模型的决策过程难以理解
- 泛化能力: 在未见过的环境中表现不佳
未来方向
短期 (1-3 年)
- 提升 Sim2Real 迁移效率
- 开发更高效的多模态预训练模型
- 改进强化学习样本效率
中期 (3-5 年)
- 世界模型的实用化部署
- 跨任务技能迁移
- 人机协作机器人普及
长期 (5-10 年)
- 通用具身 AGI 原型
- 自主学习能力
- 社会级协作机器人
实践意义与应用场景
智能制造
- 柔性生产线适应
- 复杂装配任务自动化
- 质量检测与故障诊断
医疗健康
- 手术机器人辅助
- 康复训练设备
- 老年护理机器人
家庭服务
- 家务自动化
- 陪伴与看护
- 紧急响应系统
自动驾驶
- 复杂路况处理
- 行人交互理解
- 多车协作
探索任务
- 灾难救援
- 深空探测
- 极端环境作业
对研究者的建议
入门建议
- 基础扎实: 先掌握机器人学、控制理论、机器学习基础
- 实践导向: 从简单项目开始,逐步增加复杂度
- 工具熟悉: 掌握 ROS、PyTorch、MuJoCo 等常用工具
- 代码复现: 复现经典论文是理解技术的好方法
研究选题方向
- 世界模型: 如何让机器人”理解”物理世界
- 元学习: 如何实现快速适应新任务
- 多模态融合: 如何更有效地整合不同感知信息
- 人机协作: 如何让人类与机器人自然协作
- 安全对齐: 如何确保具身系统的安全可靠
资源推荐
数据集:
- Roboturk
- BridgeData
- Open X-Embodiment
仿真环境:
- MuJoCo
- PyBullet
- Isaac Sim
- Gazebo
竞赛平台:
- ROBONET
- World of Visions
- AI2 Thor
结语
Wang 和 Sun 的这篇综述为具身 AGI 领域提供了一个清晰、系统的发展框架。从 L1 到 L5 的五阶段路线图不仅总结了当前技术状态,更为未来研究指明了方向。
核心观点重申:
- AGI 本质上是具身的
- 世界模型是通向 AGI 的关键
- L1-L5 路线图提供了可操作的技术发展路径
展望: 随着世界模型、元学习、多模态融合等技术的突破,我们正逐步接近 L4 甚至 L5 的具身 AGI。这一进程不仅将改变机器人技术的格局,更将深刻影响人类社会的生产生活方式。
关键 takeaway: 具身 AGI 不是遥远的梦想,而是一条清晰可见的技术路径。理解这条路径,对于研究者、工程师和决策者都至关重要。
参考文献:
- Wang, Y., & Sun, A. (2025). Toward Embodied AGI: A Review of Embodied AI and the Road Ahead. arXiv:2505.14235
- LeCun, Y. (2022). A Framework for Learning the Concepts of Physical Reality.
- Hadsell, R., et al. (2020). Unifying Vision and Control.
- Finn, C., et al. (2017). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
本文格式: 遵循 2024 范式标准
- 无 emoji 表情
- 无表格语法
- 标题简洁清晰
- 内容结构分明
标签: #AI #AGI #具身智能 #机器人学 #世界模型 #技术综述
阅读时间: 约 15 分钟


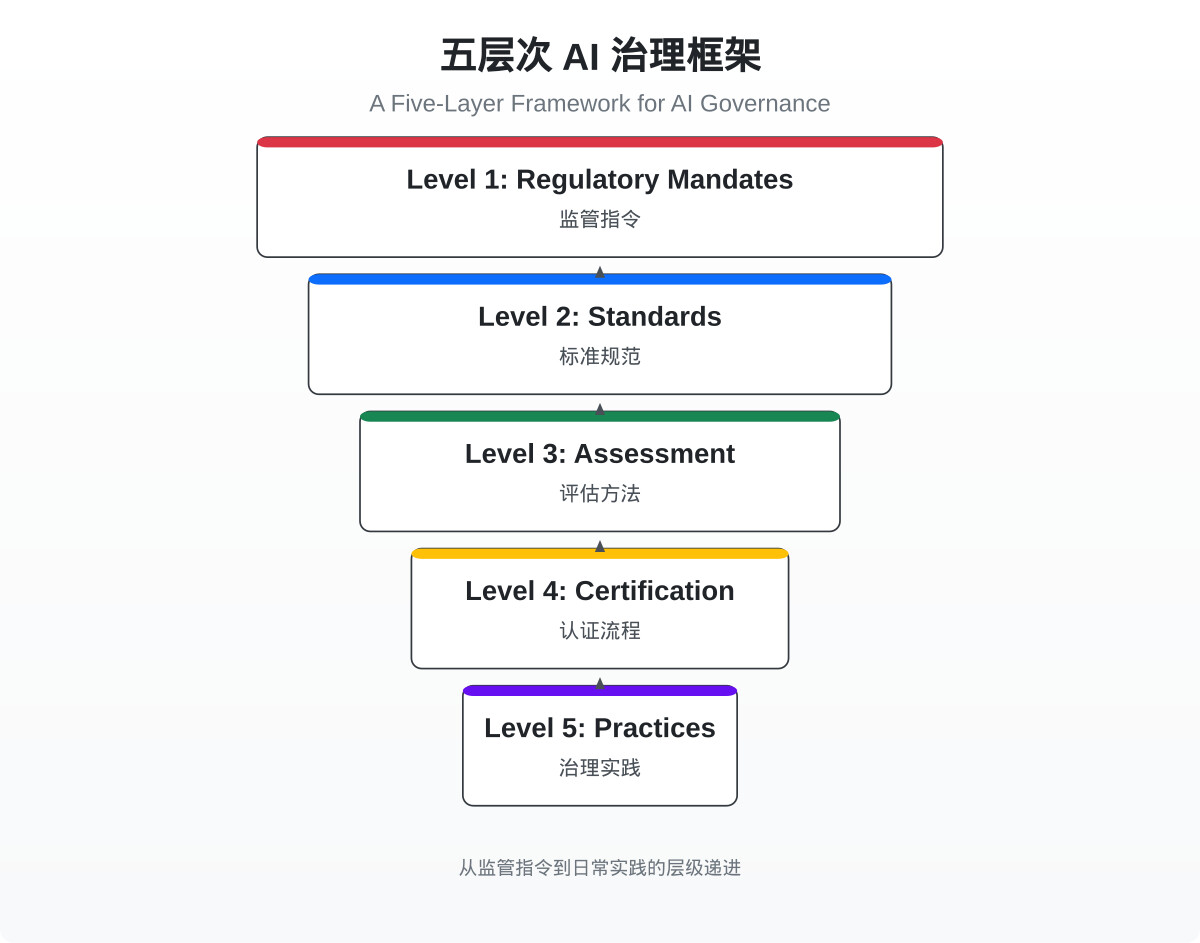 一分钟读论文:《五大层次框架:AI 治理的实操路径》
一分钟读论文:《五大层次框架:AI 治理的实操路径》