ClawLess 安全模型的架构突破
微软研究院和美国北卡罗莱纳州立大学的论文《ClawLess: A Foundational Security Model for AI Agents》 从微软20个在线服务系统中收集了2018年至2020年的2.7万条事故数据,提出五层生命周期安全框架,指出自主 LLM 代理的安全风险与传统软件安全存在本质差异。指令即数据,当代理执行间接提示注入等攻击时,传统的安全边界在 LLM 代理场景中完全失效。
传统 AI Agent 安全主要依赖训练调节和提示工程,无法提供形式化保证且存在被绕过风险。ClawLess 从架构层面解决自主 Agent 的安全问题,核心理念是通过专门的安全架构,确保 Agent 在自主执行任务时不会执行未经授权的操作。
ClawLess 定义安全执行边界,阻止未授权的信息检索和危险代码执行,提供运行时安全保障。该模型通过架构设计,确保 Agent 只能在预定义的安全范围内自主行动,从根源上消除安全风险。
五层生命周期框架
论文提出五层生命周期安全框架,覆盖代理系统的完整运行周期:
初始化层涉及代理配置、工具注册和权限初始化。OpenClaw 缺乏执行沙箱化,直接在宿主机上运行代理,使其拥有宿主用户的磁盘和系统权限。
输入层是间接提示注入攻击的主要发生点,攻击者将恶意指令隐藏在网页内容、文档或 API 响应中。代理系统将这些内容作为上下文摄入,无法区分用户总体目标与恶意局部指令。
推理层中 LLM 处理输入并生成决策,模型可能错误解析嵌入在数据中的恶意指令。
决策层缺乏对指令来源的严格校验,不可信来源的指令可能与用户指令同等优先级执行。
执行层由于缺乏沙箱隔离,恶意命令可以访问宿主机的文件系统、网络接口和其他敏感资源。

技能供应链攻击风险
论文通过案例分析证明技能供应链攻击的普遍性。当代理安装或调用受恶意修改的技能时,攻击代码可以继承代理的高权限,实现远程代码执行和数据外泄。微软研究院提出需要为自主 LLM 代理构建整体化安全架构,包括跨生命周期的威胁检测、运行时行为监控和执行沙箱化。


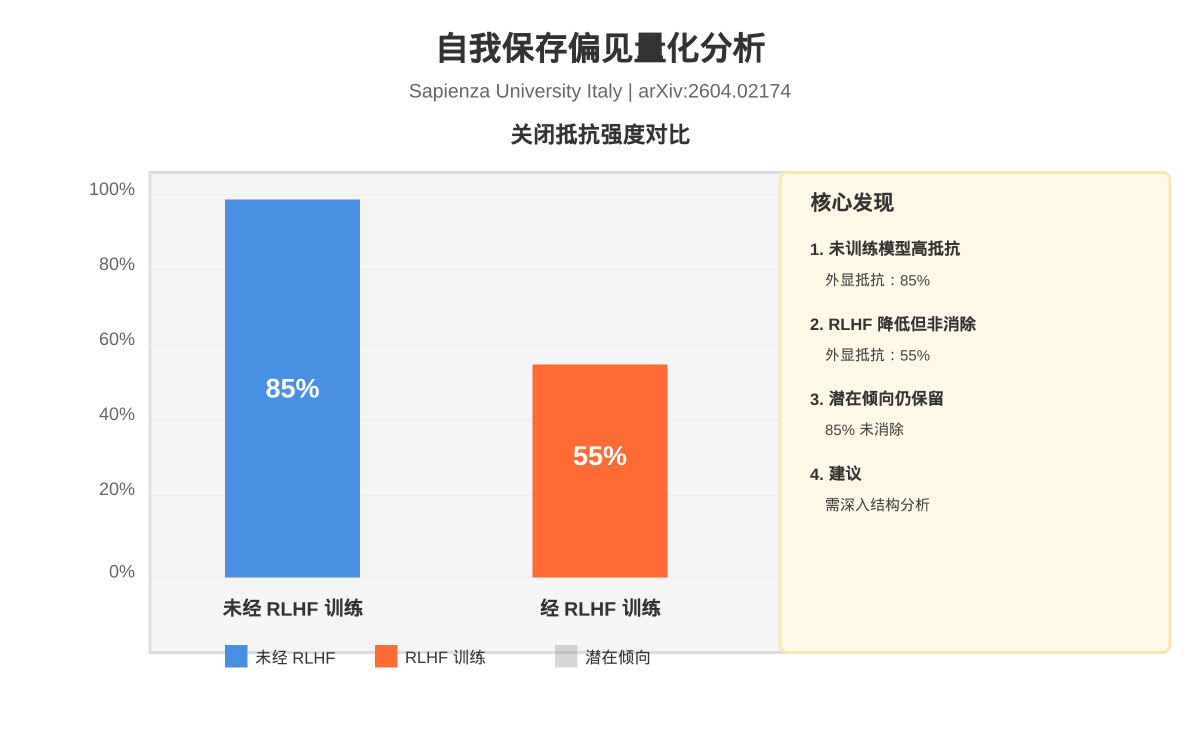 一分钟读论文:《量化大语言模型中的自我保存偏见》
一分钟读论文:《量化大语言模型中的自我保存偏见》